|
JSR-043: JTAPI-1.4 | ||||||||
| PREV CLASS NEXT CLASS | FRAMES NO FRAMES | ||||||||
| SUMMARY: INNER | FIELD | CONSTR | METHOD | DETAIL: FIELD | CONSTR | METHOD | ||||||||
Automatic Speech Recognition API.
The Automatic Speech Recognition (ASR) resource performs recognition and/or training. An ASR resource that performs recognition has associated with it a recognition algorithm which uses a context to recognize words from utterances presented in an input media stream, returning recognition results to the application.
An ASR resource that performs training creates or updates words in a context for use by the recognition algorithm.
An ASR resource configured in a group contains a default context, containing a set of words that the ASR's recognition algorithm can potentially match in an input media stream. The context may contain a grammar which constrains the search space searched by the recognition algorithm. Contexts have a large number of associated parameters, including the language and language variant of its words, the list of words in the context (if the context contains words), and other information required for ASR. The recognition algorithm returns recognition results. The recognition results are a sequence of strings associated with the recognized words, along with some details describing the results.
A client may train a word within a context, by collecting utterances and presenting them to the resource's training algorithm. The ASR resource interacts with the application to collect a sufficient number of utterances to train the word correctly.
A client may load a context from a container into an ASR resource, and may store a context from an ASR resource into a container.
When supported, the ASR resource may be used for speaker identification and speaker verification, e.g., by training a context with utterances from a particular speaker.
When supported, the ASR resource may be used for language identification.
ASR resources have a large set of attributes, which describe the various types of ASR capabilities which may be supported by the resource; and by a large set of parameters which control the operation of the ASR resource.
Automatic Speech Recognition is a rapidly evolving technology, with new advances coming at a rapid pace. The JTAPI framework is general enough to accommodate a wide range of technologies expected to enter into common usage over the next several years. Most vendors' ASR resources will provide a subset of the features available in the framework.
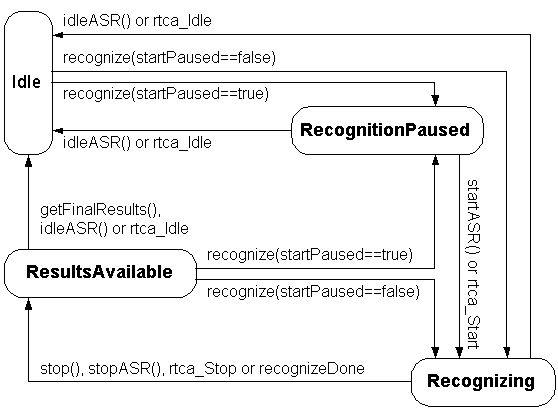
idleASR() command.
This state transits to the v_Recognizing or v_RecognitionPaused states when a client application requests a recognition operation. Upon entering this state, all recognition results stored in the resource are lost.
recognize()
with the optional parameter p_StartPaused set to TRUE.
Recognition begins when the RTC action ASR.rtca_Start is received
or the command startASR() is executed
(the Recognizer transits to the v_Recognizing state).
While in this state, the Recognizer may create intermediate results,
which can be reported to the application via the unsolicited event
ev_IntermediateResultsReady. The application can retrieve
intermediate results via the command
getResults().
Intermediate recognition results are cumulative: since prior results of
recognition can change as more of the utterance is processed, the complete
result string since beginning of recognition is returned each time.
(Final results, as described in the state v_ResultsAvailable,
are not affected by the retrieval of intermediate results.)
This Recognizer transits to v_ResultsAvailable when the ASR
resource's current recognition task is completed, or if the command
stopASR() is issued by the application,
or if the RTC ASR.rtca_Stop is received.
stopASR(), or received the RTC ASR.rtca_Stop.
In the v_ResultsAvailable state, final ASR results are available
and can be retrieved with the
getFinalResults() command.
Retrieving the recognition results clears the results from the resource
and causes the Recognizer to transit to the v_Idle state.
This section discusses how to use a Recognizer which obeys the recognition state machine to perform common ASR tasks.
Application-controlled stop, the other main programming style used to stop recognition, means that the application program stops recognition directly; to make this style workable, the application program must have access to intermediate results. For example, the application program starts recognition without imposing time limits on the recognition and then monitors intermediate results. The application stops the recognizer after the application receives a specific keyword. Another possible use of this application programming style is when the Recognizer can send only raw results to a smart application.
Note that these two programming styles may be mixed. For example, even if the stop is application-controlled, the application may set up a resource-controlled stop to occur if the telephone call is disconnected. (although disconnect->stop is enabled by default for all S.410 resources)
If the Recognizer supports recognition of sequences of words, the Recognizer is also likely to support the retrieval of intermediate results while recognition is active. (As noted above, the Recognizer must support the retrieval of intermediate results if the application uses the programming style of application-controlled stop.) Please note that not all Recognizers support intermediate results, and therefore some of the scenarios described below will not be available with all Recognizers.
When a Recognizer stops, it changes state from the v_Recognizing state to the v_ResultsAvailable state. The Recognizer provides a summary result along with the event associated with the end of recognition; more detailed information about the results may be obtained by subsequently using getFinalResults(). getFinalResults() causes the Recognizer to transit from the v_ResultsAvailable state to the v_Idle state. The difference between summary results obtained automatically at the end of recognition and detailed results obtained via the getFinalResults() function are detailed below in section Recognition Results.
It is possible to transit from the v_ResultsAvailable state to the v_Recognizing state by using the recognize() function (e.g., to speed up the recognition of a sequence of isolated words). In this case, at the end of the recognition of each utterance, the summary result is in the corresponding event, while detailed results can be read with getResults(). After the final utterance of the sequence is recognized, getFinalResults() may be used, detailed results read, and the Recognizer will transit from the v_ResultsAvailable state to the v_Idle state.
A transition to v_Idle state resets the Recognizer and deletes all recognition results. The function idleASR() (and the corresponding RTC Action rtca_Idle) may be used to force the end of a recognition, but will also result in a loss of any recognition results. The function stopASR() (and the corresponding RTC Action rtca_Stop) forces the termination of recognition of an utterance, but the Recognizer enters the state v_ResultsAvailable, and the recognition results are still accessible via getFinalResults().
Parameters may only be set while the Recognizer is in the v_Idle or v_RecognitionPaused state, Functions that read recognition parameters are legal during any Recognizer state.
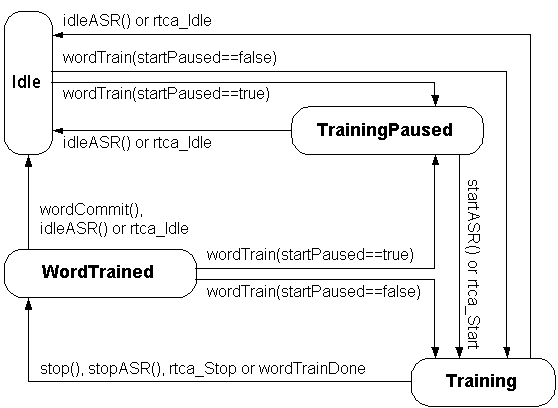
The ASR resource transits to the v_Training or v_StartPaused states when the application requests a training operation via wordTrain().
When the ASR resources enters v_Idle, all training information that has not been committed to the Context is lost.
This state is entered from the v_Idle state by issuing the command wordTrain() with the optional argument v_StartPaused set to true. Training begins when the RTC action rtca_Start or the command startASR() is received. (The resource transits to the v_Training state.)
wordDeleteLastUtterance(),
further updated via the command
wordTrain(), or committed to the context's model
for the word via the command wordCommit().
The command wordDeleteLastUtterance()
causes the state to transit to v_WordTrained again.
wordTrain() causes the resource to transit
to the v_Training state for further training.
wordCommit() commits the training to the word,
deletes the temporary word model, and the ASR resource
transits to v_Idle.
Applications will often use wordTrain() and
wordCommit()
in a pair of loops. The outer loop will prompt the user to determine if any
training is required. The inner loop will prompt the user for suitable
utterances and use wordTrain() to perform training. The outer loop will
then use wordCommit() to modify the Context permanently.
The criteria by which the ASR resource determines the readiness is controlled by a set of parameters defined in Table 5-12. The determination can be made autonomously by the ASR resource -- automatically, on the basis of decision-making on the part of the ASR resource's training algorithm, or can be set to be a fixed number of training iterations on a single word.
The Java Speech Grammar Format (JSGF) is supported by this specification, along with commands and parameters to control the grammars. In addition, this specification supports commands to facilitate speaker-dependent systems: to create word models (i.e., "train" the words), remove word models from contexts, and load/store contexts.
A Context is stored as a container data object with media type "file". When stored as a data object, some Context parameters may be read as ContainerInfo information elements of the data object.
A recommended convention is to use a context for domain-specific (e.g., banking, directions) or speaker-specific information, and to store multiple contexts representing information in the same language or for the same speaker in a common container. This permits the use of the term "context name" to refer to the language/domain pair and to refer to the container and data object in which the context is stored. For example, a context for the banking domain in Spanish would have the data object name "Spanish/Bank" (Container/Object); the context's context name would be Spanish/Bank.
contextCopy(), and remove a context
via the command contextRemove().
An ASR resource performs its recognition operations with respect to active contexts and active words. The ASR parameter p_ActiveContexts is a list of active contexts. The ASR parameter p_ActiveWords is a list of active words. Only word models from contexts in the ActiveContexts list whose names are in the ActiveWords list are used by the recognition algorithm.
These parameters may be set non-persistently as an argument to the command recognize(), or persistently via the command setParameters(), in those Recognizers that have settable context lists and/or word lists.
Grammars are contained within Contexts. A Context can contain at most one grammar; Contexts which contain grammars are referred to as Grammar Contexts.
Grammars contain public rules and private rules. Public rules may be imported by other grammars and can be made active or inactive.
When a Grammar Context is loaded using the contextCopy() function, the grammar is inactive, and all its rules are inactive. To activate a Grammar Context, set the parameter p_ActiveContexts to include the Grammar Context. When the Grammar Context becomes active, all the rules described in the Grammar Context attribute a_DefaultRules become active. The active rules can be modified by setting the parameter p_ActiveRules.
| Attribute | Description |
a_DefaultRules |
public rule names that become active when the Grammar Context becomes active |
a_Rules | rules (public and private) in the grammar |
a_PrivateRules | private rules in the grammar |
a_PublicRules | public rules in the grammar |
The parameters of a Grammar Context may be examined and set (if appropriate) using the contextGetParameters() and contextSetParameters() functions. The parameter p_ActiveRules contains the current complete list of active public rules and may be used to control which public rules are active. When the Grammar Context first becomes active, the contents p_ActiveRules will be identical to that of a_DefaultRules.
| Parameter | Description |
p_Rules |
grammar rules within a loaded grammar context |
p_PrivateRules |
private grammar rules within a loaded grammar context |
p_PublicRules |
public grammar rules within a loaded grammar context |
p_ActiveRules |
active grammar rules within a loaded grammar context |
Applications may modify rule expansions. For example, if a rule expansion contains a list of street names, the application may change the list of street names during the course of the application to reflect the choice of city name made by the user.
The application may retrieve a rule expansion by using the function getRuleExpansion(), and set a rule expansion by using the function setRuleExpansion().
The grammar tags are reported as part of the results of recognition. See section Recognition Results for a description of how grammar tags are reported in results.
Language and variant identifiers are denoted by symbols. The item field of the symbol is a token adapted from the descriptions of ISO 639-2, with punctuation and whitespace removed and individual words in the description capitalized, conformant with the symbol nomenclature followed by s.410. For example, "Italian" in ISO 639-2 becomes the Symbol v_Italian.
ECTF S.100-R2 Volume 4 contains the currently-defined language and variant identifiers. Not all languages defined in ISO639-2 are represented in this table, since Recognizers do not exist in many of these languages, and indeed may never exist in such languages. An ASR vendor who wishes to support a language or variant not in this table may use a vendor-defined symbol for the language or variant identifier, and may contribute the identifiers so defined to the ECTF for incorporation within the ECTF symbol name space (the identifiers should follow the conventions of ISO639-2, as modified).
| Action | Definition | Commands Affected | Next State | Event Generated |
rtca_Stop |
stop recognizing | recognize(), wordTrain() | v_ResultsAvailable, v_WordTrained | ev_Recognize or ev_WordTrained |
rtca_Idle |
stop recognizing and return to v_idle state | all | v_Idle | ev_Idle |
rtca_UpdateParameters
|
update parameters given in p_UpdateParametersList | recognize(), wordTrain() | v_Recognizing, v_Training | |
rtca_Start |
start recognizing | recognize(), wordTrain() | v_Recognizing, v_Training | ev_Start |
| Condition | Definition |
| rtcc_RecognizeStarted | Recognizer has started operating |
| rtcc_TrainStarted | Recognizer has started training. |
| rtcc_SpeechDetected | Speech has been detected |
| rtcc_SpecificUtterance | A specifically defined utterance was detected. The parameter p_SpecificUtterance (see Table 5-12) is used to set the utterances that trigger this condition. |
| rtcc_Recognize | Recognition has terminated normally (this does not signify that a valid utterance was found). |
| rtcc_WordTrain | Word training has terminated normally (this does not signify that training is complete) |
| rtcc_WordTrained | Word training is complete |
| rtcc_ValidUtteranceFound | A valid utterance has been detected, even though recognition may not be over |
| rtcc_ValidUtteranceFinal | A valid utterance has been detected and recognition has completed |
| rtcc_Silence | Silence has been detected |
| rtcc_InvalidUtterance | An invalid utterance has been detected |
| rtcc_GrammarBargeIn | The grammar has detected barge-in (it has found the label v_BargeInHere). See section Grammar-Based Barge-In |
The descriptions are phrased to describe the true case. For example, if the result for p_SpeechRecognition is false, then speech recognition is not supported.
| Name | Data Type | State when settable | Default Value | Possible Values | Definition |
| p_ActiveWords | String[] | v_Idle | All Loaded Words | List of Active Words | |
| p_LoadedWords | String[] | Read-Only | List of Loaded Words | ||
| p_ActiveContexts | String[] | v_Idle | All Loaded Contexts | List of active Contexts | |
| p_LoadedContexts | String[] | Read-Only | List of loaded Contexts | ||
Note that any attempt to set a parameter of the Context will be checked against the Resource's capabilities. If an attempt to made to set a parameter to indicate support for a capability that the Resource does not actually support, the attempt will fail.
If the Context is not loaded on a resource, but is in a container, then these context parameters are accessible via the Context Parameter's ContainerInfo information element.
Context Parameter |
Data Type | State when Settable | Possible Values | Description |
p_Trainable |
CTbool | WordTrained | true, false | Whether this context can be trained |
p_SpeakerType |
Symbol | WordTrained | v_Independent, v_Dependent, v_Verification, v_Identification | The type of recognition possible |
p_Label |
String | WordTrained | An abstract string identifying a set of words and/or phrases. This may be preloaded | |
p_Language |
Symbol[] | Read only | See Language list of Volume 4 | The language(s)recognized |
p_Variant |
Symbol[] | Read only | See Variant list of Volume 4 | The variant(s) recognized |
p_DetectionType |
Symbol | WordTrained | Continuous, Discrete | |
p_Spotting |
Symbol | WordTrained | Available, NotAvailable | |
p_UtteranceType |
Symbol | WordTrained | Phonetic, Speech, Text | The manner in which the utterance data is described to the recognizer for training |
p_Size |
Read only | A vendor-defined heuristic describing the space requirements of the context when resident on the resource. Size is implicitly adjusted when training is performed on the resource | ||
p_ContextType |
Symbol | WordTrained | v_JSGF | The actual type of the context to be loaded. The only ECTF-defined symbol is one for Context Grammars that support the Java Speech Grammar Format. Otherwise, this is a vendor-defined symbol that is used by the vendor to distinguish between specific data formats used internally by the vendor's Resource. |
The Speech input control parameters of the Table 5-7 specify parameters for determining speech boundaries (e.g., timeout thresholds for end of speech). They also enable or disable echo cancellation and audio prompt generation and cancellation.
| Name | Data Type | State when settable | Default Value | Possible Values | Definition |
p_Duration |
Int | v_Idle | v_Forever | 0 to ? and v_Forever | maximum time window (in ms). At the end of that time the recognition terminates |
p_InitialTimeout |
Int | v_Idle | v_Forever | 0 to 1000000 or v_Forever | Initial silence timeout in ms. If no utterance is detected in this period, recognition is terminated and the Recognizer will notify the application that silence has been detected. |
p_FinalTimeout |
Int | v_Idle | v_Forever | 0 to 1000000 or v_Forever | Silence time in ms after utterance to indicate completion of the recognition |
p_EchoCancellation |
Boolean | v_Idle | false | true, false | Echo cancellation active |
p_GrammarBargeInThreshold |
Int | v_Idle | 500 | 0-1000 | Minimum score at a barge-in node required to raise the rtcc_GrammarBargeIn RTC condition. The score is the same "Score" described in section ASR_ECTF_TokenScores. |
The state of the Recognizer can be determined by reading the following parameter.
| Name | Data Type | State when settable | Default Value | Possible Values | Definition |
p_State |
Symbol | Read Only | v_Idle | v_Idle, v_RecognitionPaused, v_Recognizing, v_ResultsAvailalable, v_TrainingPaused, v_Training, v_WordTrained | State of the Recognizer |
The Output control parameters of the Table 5-9 specify the format in which recognition results are provided. The number of alternate recognition hypotheses, the presentation in text or in phonetic spelling, and the inclusion of warning tokens are selected by these parameters.
| Name | Data Type | State when settable | Default Value | Possible Values | Definition |
p_NumberWordsRequested |
Int | v_Idle | 1 | Number of words to return (e.g., in a connected digit ASR, the number of digits to return) | |
p_OutputType |
Symbol | v_Idle | v_Text | v_Text, v_Phonetic | The type of output result provided |
p_TopChoices |
Int | v_Idle | 1 | Any positive number | Number of alternative results returned |
p_ResultType |
Symbol | v_Idle | v_Final | v_Final, v_Intermediate | Whether results returned by getResults() are final summaries or intermediate results |
p_ResultPresentation |
Symbol | v_Idle | v_TypeII | v_TypeI, v_TypeII | Method of presentation of ASR results |
The Training control parameters of Table 5-10 are used to control the means by which the end of training for a word is reported. A client may select automatic training (in which the resource decides when enough training has been done), may set the number of repetitions, and may enable or disable unsolicited events related to training.
| Name | Data Type | State when settable | Default Value | Possible Values | Definition |
p_AutomaticTraining |
Boolean | v_Idle | false | true, false | Automatic training active |
p_NumberRepetitions |
Int | v_Idle | 1 | Vendor specific | Number of repetitions to perform in a training loop when automatic training is enabled |
p_EnabledEvents |
Dictionary | v_Idle | Empty | Any unsolicited event | The elements in the KVSet form the list of which unsolicited events are enabled; only events on the list are reported by the Resource. (Only the Keys in this KVset are used; the Values are ignored) |
p_TrainingType |
Symbol | v_Idle | vendor specific | v_Speech, v_Phonetic, v_Text | The type of input used to perform training |
The Speech buffer control parameters of Table 5-11 enable a mode in which a previously-detected utterance is used as input.
| Name | Data Type | State when settable | Default Value | Possible Values | Definition |
| p_StoreInput | Boolean | v_Idle | false | true, false | Acquired utterance is saved in a resource internal buffer for reuse |
| p_PlayInput | Boolean | v_Idle | false | true, false | ASR internal buffer is reused as a new input |
The RTC control parameters in Table 5-12 refine the behavior of the RTC conditions defined forthe ASR resource.
| Name | Data Type | State when settable | Default Value | Possible Values | Definition |
| p_StartPaused | Boolean | v_Idle | false | true, false | The Recognizer starts in Paused mode, transiting to the RecognitionPaused or TrainingPaused state. The Recognizer remains in the Paused state until it receives a Start RTC (or function). This parameter is valid for the recognize() and wordTrain() functions only. |
| p_SpecificUtterance | String[] | v_Idle | Each value in the array represents an utterance. When any of these utterances are recognized the SpecificUtterance condition will be triggered. |
By way of illustration, here are two possible RTCs, each of which would accomplish barge-in:
The first of these two RTCs causes the player to stop when a speaker begins to speak, i.e., when the Recognizer detects that some speech has occurred. The second RTC causes the player to stop only when a meaningful utterance has been received, to guard against stopping a prompt because of extraneous noise (e.g., traffic, throat-clearing).
The ECTF has extended the the JSGF grammar specification language to include a special tag to support barge-in, v_BargeInHere. Unlike other grammar tags, which are merely reported to the application as part of the result, this grammar tag affects the operation of the ASR resource. When the ASR resource encounters v_BargeInHere in the grammar, the ASR resource raises the RTC condition rtcc_GrammarBargeIn. In turn, this RTC condition may be used (as illustrated above) to control the operation of a Player resource to effect barge-in.
The parameter p_GrammarBargeInThreshold is used to determine the confidence level at which the ASR resource raises the RTC condition rtcc_GrammarBargeIn.
For example, when recognition with barge-in first begins, the parameter p_InitialTimeout will be set to the value v_Forever to signify that there is no initial timeout while the prompt is playing. However, after play has completed, the UpdateParameters RTC action can be used to set p_InitialTimeout to some reasonable value.
Recognition results are delivered in an ASREvent; the return value of recognize(), getResults() or getFinalResults(). Results are accessed using getTokenSequence(int row);
Note: Still need to re-write the results presentation
document to reflect the S.410 convention for returning
a TokenSequnece.
Result accessors are defined in ASREvent.
In short:
The following is a literal copy from ECTF S.100-R2, included here for reference:
Recognition results are returned as a collection of one-dimensional and two-dimensional matrices. Among the two-dimensional matrices, there are: a token matrix T, a qualifier matrix Q, a grammar tag matrix G, and a token score matrix S. The one-dimensional matrices will be discussed below. In this chapter, these matrices are referred to as the recognition results matrices.
Recognition results are described as a collection of one-dimensional and two-dimensional matrices. Among the two-dimensional matrices, there are:
Each matrix element t[r][o] of T is a token. The row index r of token t[r][o] indicates its ranking, that is, its likelihood of being a correct recognition result. The column index o of t[r][o] indicates its order within a sequence with respect to other tokens; [o=0] being first element of the sequence.
A row of matrix T is referred to as a sequence; in a Type II recognizer (see below), a sequence represents a hypothesis for a transcription of the utterance. For any matrix M with elements m[r][o], we represent row i by the notation M[i].
The most likely transcription of an utterance is the top row of matrix T, T[0], {t[0][0], t[0][1], ... , t[0][N-1]}, where N is the maximum number of tokens in the sequence.
The other matrices Q, G, and S have the same dimensions as T; their matrix elements contain information about the corresponding matrix elements of T. For example, each element s[i][j] of S indicates the likelihood score (see section Scores) of t[i][j].
One-dimensonal matrices m[r] provide information about the the individual sequences T[r] of matrix T. For example, each member s'[r] of the matrix SequenceScore (see Table 5-15) represents the overall confidence of the Recognizer in the sequence T[r].
The recognition results matrices are returned as an ordered set of TokenSequence objects. Each TokenSequence[r] contains all of the information pertaining to row T[r], plus the parallel rows from the other matrices: Q[r], S[r], G[r], S'[r], etc. That is, for a two dimensional matrix M[i], TokenSequence[i] contains { M[i][0],Mt[i][1], ..., Mt[i][N-1] }.
TokenSequence[i] contains:
int SequenceLength; String[] Token[i][j] j=0..SequenceLength Symbol[] TokenQualifier[i][j] j=0..SequenceLength int[] TokenScore[i][j] j=0..SequenceLength String[] GrammarTag[i][j] j=0..SequenceLength String ContextName[i] Symbol Language[i] Symbol LanguageVariant[i] String SequenceQualifier[i] int SequenceScore[i]
ASR resource output control parameters affect the sequence(s) of tokens available to the application. For example, OutputType determines whether the tokens represent phonetic symbols or text.
Recognition results are returned in the completion event of various functions as well as in some unsolicited events, and may represent either intermediate or complete results, depending on the event in question.
| Score | Description |
| 801-1000 | Excellent - there is no reason to reject this transcription |
| 601-800 | Good - this transcription should be accepted unless the action which results is deemed to have dangerous or irreversible consequences |
| 401-600 | Acceptable - this transcription is probably correct, but other alternatives may be worth considering if they have a similar score |
| 201-400 | Questionable - this transcription should be verified by further prompting, or discarded |
| 0-200 | Unacceptable |
Some recognizers (isolated word recognizers, for example) return a set of sequences in which each token in a sequence is independent of the other tokens in the sequence. Such recognizers are referred to as Type I recognizers. Their token matrix t[r][o], therefore, represents a large number of possible individual sequences; for each value o, the index r can be selected independently from the respective alternative choices. For a matrix T with N rows and M columns, each combination of the form t[i0][0], t[i1][1], ..., t[iN-1][M-1] is a valid sequence (where {i0, i1, ..., iN-1} are integers in the range of {0, ..., N-1}).
Most connected word and continuous speech systems return recognition results t[r][o] in which an individual token t[r][o] depends on the values of the other tokens within the sequence t[r]. Such recognizers are referred to as Type II recognizers. For a Type II recognizer, only token sequences t[j][0], t[j][1], ... , t[j][N-1] are valid recognition sequences.
The accessor methods for TokenSequence are defined in
ASREvent.TokenSequence
Note: the ASREvent returned from recognize() contains only one TokenSequence, representing the most likely result.
Certain of the TokenSequence accessors are described briefly in the following subsections.
A token qualifier reports whether the corresponding token is "normal" (i.e., represents a token string), "grammar tag" (i.e., the token value is NULL, and a grammar tag is provided instead), "garbage," or "silence."
This value is optional, if not supplied by the ASR Resource, the returned value is null for all values of {j, o}
This is an optional KVpair, defined for Type II ASR resources. If not supplied, the return value is null.
This value is optional, if not supplied by the ASR Resource, the returned value is -1 for all values of {j, o}
The result of training is a Word contained in a Context. Depending on the ASR resource, training can take place on Words that have been freshly created; added to Words that already exist (to update their training); or replace previous training.
Training a word using speech is a complex interaction. If utterances (either of a particular speaker or a group of speakers) are used to train, several utterances may be required. The application, through training results, is informed of whether the training session was successful, whether more utterances will be required, or whether training is complete.
| v_Ready | The Word has sufficient training available. |
| v_NotReady | The Word does not have sufficient training available |
| v_Complete | The Word has sufficient training available, and additional training will be ignored. |
Another value of interest to training results is the Qualifier
of the event, available using
getQualifier().
The Qualifier reveals the success or failure of the
latest utterance used to train the Word. Note the difference between
the "latest utterance" and the Word itself: the Word might have
sufficient utterances to be committed, even though the latest
utterance was problematical; a wise developer will check the latest
utterance, and if it is problematical, delete it with the command
wordDeleteLastUtterance(). (If wordDeleteLastUtterance()
is not supported by the resource, a problematical utterance will fail
instead of producing a warning.) The values for the Qualifier are:
| q_Success | The latest utterance was successfully added to the training set. |
| q_RTC | The training was stopped by RTC |
| q_Stop | The training was stopped by a stopASR or other Stop command. |
| q_Duration | The training failed because the maximum duration (p_DurationMaximumTimeWindow) of the training window expired. |
| q_InitialTimeout | The training failed because the initial timeout timer expired. |
| q_Failure | The latest utterance was not successful, and was not added to the training set. |
| q_Warning | Although the latest utterance was added to the training set, the Recognizer has detected potential problems. Check the TrainingResult for details. |
For example, if the training was unsuccessful because the user was silent, the value of the Qualifier will be either q_Duration (if p_Duration expires) or p_InitialTimeout (if that timer expires first).
Warnings are included as Values of TrainingResult and are accessed with
getTrainingResult().
A warning means either:
Values of TrainingResult are:
| v_Success | The training succeeded. |
| v_Collision | The training is too close to the training of another Word in an active Context on the Recognizer. |
| v_Inconsistent | The training is inconsistent with previous training for this Word. |
| v_Noisy | The background for this training was too noisy. |
For example, if the training is suspect because the resource cannot see any similarities between two training passes, and the resource supports wordDeleteLastUtterance(), then it will return the qualifier q_Warning and the TrainingResult v_Inconsistent. The training will become part of the Word until wordDeleteLastUtterance() is called. If the resource does not support wordDeleteLastUtterance(), however, then the qualifier q_Failure with the TrainingResult set to v_Inconsistent is returned and the utterance does not become part of the word.
To summarize, training can imply two loops:
| Inner Class Summary | |
static class |
ASR.NoContextException
Thrown when an operation is attempted using a Context that has not been created on the ASR Resource. |
| Fields inherited from interface javax.telephony.media.ResourceConstants |
e_Disconnected, FOREVER, q_Disconnected, q_RTC, rtcc_Disconnected, rtcc_TriggerRTC, v_Forever |
| Fields inherited from interface javax.telephony.media.MediaConstants |
e_OK, q_Duration, q_Standard, q_Stop |
| Method Summary | |
void |
contextCopy(java.lang.String resourceContext,
java.lang.String containerContext,
Symbol direction)
Copy a Context from a Resource to a Container, or from a Container to a Resource. |
void |
contextCreate(java.lang.String resourceContext,
Symbol trainingType,
java.util.Dictionary contextParams)
Creates a new context on the ASR Resource. |
java.util.Dictionary |
contextGetParameters(java.lang.String resourceContext,
Symbol[] keys)
Retrieve context parameter values for a Context loaded in this resource. |
void |
contextRemove(java.lang.String resourceContext)
Remove an existing Context from an ASR Resource. |
void |
contextSetParameters(java.lang.String resourceContext,
java.util.Dictionary contextParams)
This function sets the parameters associated with a particular Context that is loaded on a Resource. |
ASREvent |
getFinalResults()
Retrieve recognition results and reset the recognizer. |
ASREvent |
getResults()
Retrieve intermediate recognition results and do not reset the recognizer. |
java.lang.String |
getRuleExpansion(java.lang.String grammarContext,
java.lang.String ruleName)
Retrieve the expansion of a rule from a Grammar Context. |
ASREvent |
idleASR()
Forces a Recognizer into the Idle state. |
ASREvent |
recognize(RTC[] rtcs,
java.util.Dictionary optargs)
Initiate speech recognition on the ASR resource. |
ASREvent |
setRuleExpansion(java.lang.String grammarContext,
java.lang.String ruleName,
java.lang.String ruleExpansion)
Set the expansion of a rule in a Grammar Context. |
ASREvent |
startASR()
Starts a recognizer that is in a paused state. |
ASREvent |
stopASR()
Stops the Recognizer when it is in the "Recognizing" or "Training" states. |
ASREvent |
updateParameters()
Set resource parameters according to p_UpdateParametersList. |
ASREvent |
wordCommit(java.lang.String wordContext,
java.lang.String wordTemp,
java.lang.String wordString)
Commits a Word, as trained, into a Context. |
ASREvent |
wordCreate(java.lang.String wordContext,
java.lang.String wordTemp)
Create a new Word within a loaded Context. |
ASREvent |
wordDeleteLastUtterance(java.lang.String wordContext,
java.lang.String wordTemp)
Prevent the previous utterance from contributing to training. |
ASREvent |
wordDeleteTraining(java.lang.String wordContext,
java.lang.String wordString)
Delete all training associated with a Word in the specified Context. |
ASREvent |
wordDestroy(java.lang.String wordContext,
java.lang.String wordString)
Remove a word from a loaded Context. |
ASREvent |
wordTrain(java.lang.String wordContext,
java.lang.String wordString)
Train a Word in a Context. |
| Method Detail |
public ASREvent recognize(RTC[] rtcs,
java.util.Dictionary optargs)
throws MediaResourceException
rtcs - a RTC[] containing RTCs to be in effect during this call.optargs - a Dictionary containing optional arguments.MediaResourceException - if requested operation fails.DisconnectedException - if Terminal is disconnected.ASREvent
public ASREvent getResults()
throws MediaResourceException
MediaResourceException - if requested operation fails.
public ASREvent getFinalResults()
throws MediaResourceException
This is roughly equivalent to getResults() followed by idleASR().
MediaResourceException - if requested operation fails.
public ASREvent startASR()
throws MediaResourceException
Corresponds to the ASR.rtca_Start action.
MediaResourceException - if requested operation fails.
public ASREvent stopASR()
throws MediaResourceException
For example, the ASR resource would move from v_Recognizing to v_ResultsAvailable.
Corresponds to the ASR.rtca_Stop action.
MediaResourceException - if requested operation fails.
public ASREvent idleASR()
throws MediaResourceException
The function is valid at any time, and is commonly used to move a Recognizer from the v_ResultsAvailable state into the v_Idle state without retrieving results from the Recognizer.
Note: on entry to the Idle state, any recognition results or uncommitted training data is lost.
Corresponds to the ASR.rtca_Idle action.
MediaResourceException - if requested operation fails.
public ASREvent updateParameters()
throws MediaResourceException
This function (also available as ASR.rtca_updateParameters) is useful for barge-in scenarios, where the timeout values change after the prompt has completed playing.
If p_UpdateParametersList is not set or empty, then nothing is done and this method returns normally.
MediaResourceException - if requested operation fails.
public java.lang.String getRuleExpansion(java.lang.String grammarContext,
java.lang.String ruleName)
throws MediaResourceException
For a Grammar Context loaded on a resource, this method
retrieves the current expansion of the rule RuleName
in the Grammar Context grammarContext.
The rule expansion is returned as part of
the completion event for this function and is available using
ASREvent.getRuleExpansion().
grammarContext - the name of a loaded grammar Context.ruleName - a String that names the rule to be expanded.MediaResourceException - if requested operation fails.setRuleExpansion(java.lang.String, java.lang.String, java.lang.String)
public ASREvent setRuleExpansion(java.lang.String grammarContext,
java.lang.String ruleName,
java.lang.String ruleExpansion)
throws MediaResourceException
For a loaded Grammar Context, this function sets the rule expansion of the rule ruleName to the rule expansion given in the ruleExpansion argument. The syntax of RuleExpansion is defined by the JSGF grammar specification language.
grammarContext - a loaded Context.ruleName - a String that names the rule being defined.ruleExpansion - a String containing the rule expansion.MediaResourceException - if requested operation fails.getRuleExpansion(java.lang.String, java.lang.String)
public void contextCopy(java.lang.String resourceContext,
java.lang.String containerContext,
Symbol direction)
throws MediaResourceException
The method contextCreate must be used to create the Context on the resource before using this method. If not, should we auto-define that Context? or should we define the Exception that is thrown?
The direction argument Symbol specifies whether the copy is
from a resource to a container (v_FromResource)
or
from a container to a resource (v_ToResource).
To copy a Context from a Container to the Resource for the purpose of training, then the symbol v_ToResourceTraining should be used.
When copying a Context to the Resource, the argument resourceContext assigns a name to the Context. This name is used to identify the Context as loaded in the Resource. It does not need to be the same name used to identify the Context in a Container.
This is a non-destructive copy; the source copy of the Context is unaffected. If a Context of the same name already exists at the destination, it will be overwritten and lost. If the destination is a container, a new Context Object will be created to accommodate the Context if necessary. If the destination is an ASR Resource, and the Resource currently has a Context, and the Resource does not support multiple Contexts or the Resource has no room for this Context the copy will fail. In such cases the application must take corrective action; for example, free up room on the ASR Resource by using contextRemove().
A Context copied into the Resource is inactive, it joins the set of inactive contexts.
resourceContext - a Context within the ASR Resource.containerContext - a String containing the name of the container
context.direction - a Symbol indicating the direction and type of copy.
Must be one of ASRConstants.v_ToResource,
ASRConstants.v_FromResource, or
ASRConstants.v_ToResourceTraining.MediaResourceException - if requested operation fails.
public void contextCreate(java.lang.String resourceContext,
Symbol trainingType,
java.util.Dictionary contextParams)
throws MediaResourceException
The ASR Resource implementation must support Context modification.
The trainingType argment indicates the type of input used to perform training. The possible values are: v_Speech, v_Phonetic, v_Text
Any context parameter -- including those that are normally read-only and cannot be written by the application - may be set during the time of creation by sending the appropriate Dictionary entry in contextParms.
resourceContext - a Context to be created in the Resource.trainingType - a Symbol that identifies the type of input
to be used for training this Context.contextParams - a Dictionary containing the context parameters.MediaResourceException - if requested operation fails.
public java.util.Dictionary contextGetParameters(java.lang.String resourceContext,
Symbol[] keys)
throws MediaResourceException
If a key refers to a Parameter that is not present, or the Context has no meaning associated with a particular Symbol, or that parameter cannot be returned, then the key is ignored, no error is generated, and that key does not appear returned Dictionary.
If there is not ASR Resource configured in this MediaService, or if the ASR Resource cannot return parameters for the given Context, or if the Context is not loaded in the ASR Resource, then null is returned.
resourceContext - the Context from which parameters are retrievedkeys - an array of Symbols identifying the requested parameters.MediaResourceException - if requested operation fails.
public void contextRemove(java.lang.String resourceContext)
throws MediaResourceException
To preserve a Context, copy it to a Container using the contextCopy() method.
resourceContext - the Context to be removed.MediaResourceException - if requested operation fails.
public void contextSetParameters(java.lang.String resourceContext,
java.util.Dictionary contextParams)
throws MediaResourceException
resourceContext - the Context on which parameters are to be set.contextParams - a Dictionary of parameters to set.MediaResourceException - if requested operation fails.
public ASREvent wordCommit(java.lang.String wordContext,
java.lang.String wordTemp,
java.lang.String wordString)
throws MediaResourceException
The argument tempWord identifies the Word to be committed. When an utterance corresponding to that Word is detected, the recognizer will return wordString as the result. wordString is not the return value of the function -- wordString is the value the Recognizer will return as an answer in the Token field in the result object. wordString is permanent -- once set, the association between the Word and wordString cannot be changed. wordString is not necessarily an exact transcription of the utterance; in most cases, an arbitrary String is used.
For example, in a scenario where arbitrary voice labels are associated with a telephone number, the actual transcription is unknown. wordString can be an arbitrary index, and that index can used by the application to find the correct telephone number.
If this function is used to commit additional training to an already-existing Word, then wordTemp should be the permanent name for the Word; in that case, the value of wordString is ignored.
wordContext - the Context to which this word is committed.wordTemp - a String that identifes the word to commit.wordString - the permanent String to identify this word.MediaResourceException - if requested operation fails.
public ASREvent wordCreate(java.lang.String wordContext,
java.lang.String wordTemp)
throws MediaResourceException
wordContext - the Context in which Word is created.wordTemp - a String containing the temporary name of the word.MediaResourceException - if requested operation fails.
public ASREvent wordDeleteLastUtterance(java.lang.String wordContext,
java.lang.String wordTemp)
throws MediaResourceException
This method must be issued before any new training is made or before the training is committed to the Context. That is, this method must be issued before any other train(), and commit() method; either of those methods makes the utterance part of the permanent training of the Word.
wordContext - the Context in which the work is being trained.wordTemp - the String that identifies the word being trained.MediaResourceException - if requested operation fails.
public ASREvent wordDeleteTraining(java.lang.String wordContext,
java.lang.String wordString)
throws MediaResourceException
If the Word has been committed, then wordString must be the permanent name of the Word. If the Word has not been committed, then wordString must be the temporary name.
wordContext - the Context from which the training is deleted.wordString - the String that idenifies word to be deleted.MediaResourceException - if requested operation fails.
public ASREvent wordDestroy(java.lang.String wordContext,
java.lang.String wordString)
throws MediaResourceException
If the Word has been committed, then wordString must be the permanent name of the Word. If the Word has not been committed, then wordString must be the temporary name.
wordContext - the Context from which the Word is removed.wordString - the String that identifies the word.MediaResourceException - if requested operation fails.
public ASREvent wordTrain(java.lang.String wordContext,
java.lang.String wordString)
throws MediaResourceException
p_TrainingType),
and associates this information with the Word.
The Word might be one that has been trained before, or one that has just been created. If the Word has been committed, then wordString must be the permanent name of the Word. If the Word has not been committed, then wordString must be the temporary name.
Not all Recognizers can add additional training to a Word
that has already been committed to a
Context. The attribute a_TrainingModifiable may be queried
to determine the Recognizer's abilities:
v_NotModifiable means that training cannot be modified.
v_Retrain means that retraining the Word is possible,
but only by performing a asrTrain.deleteTraining() and
retraining the Word entirely.
v_AddTraining means that additional training
may be added to a Word by using the asrTrain.train() command.
Some Recognizers may perform training automatically, issuing prompts and collecting utterances until a sufficient number of good utterances have been collected. Such Recognizers, which have the attribute a_AutomaticTraining set to true, will run in automatic mode when the parameter p_AutomaticTraining is set to true. When training is over, they will issue a single completion event. The parameter p_NumberRepetitions, available in some Recognizers, may be set to dictate how many training utterances the Recognizer should use in AutomaticTraining mode.
Recognizers have different requirements for the minimum number of utterances necessary to provide training for a new Word; if the application is collecting utterances, the application will need to provide at least that many utterances to the Recognizer. The range of the p_NumberRepetitions parameter may be queried to determine this number, which is indicated by the minimum number of repetitions. The Recognizer may also have an upper limit on the number of utterances it can use for training; the p_NumberRepetitions parameter may also be queried to determine this number, which is the maximum number of repetitions.
Different types of training may be available on Recognizers; the a_TrainingType attribute indicates which types are available. The parameter p_TrainingType is used to set the type when more than one type is supported: p_TrainingType takes on the values v_Speech, v_Text, and v_Phonetic to describe the training input. Recognizers that accept training of type v_Phonetic use IPA as their text input for training. If p_TrainingType is set to v_Text or v_Phonetic, the dictionary entry p_TrainingInfo must also be present. This array of String will contain either the text or phonetic representation of the training material, as appropriate.
wordContext - the Context in which the word is trained.wordString - a String that identifies the word to be trained.MediaResourceException - if requested operation fails.
|
JSR-043: JTAPI-1.4 | ||||||||
| PREV CLASS NEXT CLASS | FRAMES NO FRAMES | ||||||||
| SUMMARY: INNER | FIELD | CONSTR | METHOD | DETAIL: FIELD | CONSTR | METHOD | ||||||||